DBT (Data Build Tool) - 101
SQL for Product Level들어가며,
- 데이터 분석가로 일하며 겪은 문제 중 하나는
- 온전한 제품을 제공하고 운영하는 과정은 일반적인 개발자와 다름없음에도 불구하고 기반한 문서나 코드의 퀄리티가 개발을 업으로 하는 사람들과 큰 차이를 보인다는 점
- 분석의 과정이 정형화되어 있지 않고 / 다양한 모습의 산출물로 요구되기 때문이기도 하고 / 기반한 기술들이 아직 성숙하지 않은 문제도 있기 때문
- 개인적으로 SQL 작성 시에 이러한 문제와 한계를 많이 체감했다.
- SQL이 업무의 산출물인 경우
- 주로 성능과 안정성을 고려해 작성되는 SQL, 가독성이 떨어지며 유지보수 또한 어려움
- 하나의 코드 뭉치에 복잡한 로직이 엉켜있어 일부의 로직 수정이 코드 전반에 걸친 대대적인 수정을 필요로 하고, 전체를 재작성하는 것이 더 빠른 상황이 자주 나옴.
- 문제 해결을 위해
- 작성된 로직에 오류는 없는지 동료의 리뷰가 필요했고,
- 변경된 로직에 따라 수정된 내역을 보관하고 기록할 수 있도록 버전 관리가 필요했고,
- 이상 데이터가 포함되어 오류가 발생하는지 모니터링도 필요하며,
- 여타 다른 개발 언어와 같은 수준의 편의 기능들이 필요했다.
- 동시에 동료, 외부 조직의 접근성을 높일 수 있도록 출력 결과에 대한 안내, 문서화가 필요했다.
- dbt는 이런 문제들을 모두 해결하기 위한 도구였고 큰 기대를 하고 보기 시작했다.
About dbt
- ELT(Extract, Load, Transform) 중에서 T(Transform)를 위해 제작된 도구
- ETL → ELT로의 변화, 혹은 그 이후의 개선을 위해 DBT와 같은 Transform만을 위한 도구가 대두된 것
- 외부 데이터 소스로부터 데이터를 추출하거나 적재하는 기능 부재
- 이미 적재되어 있는 데이터를 조회하고 수정하는 데에 최적화된 도구
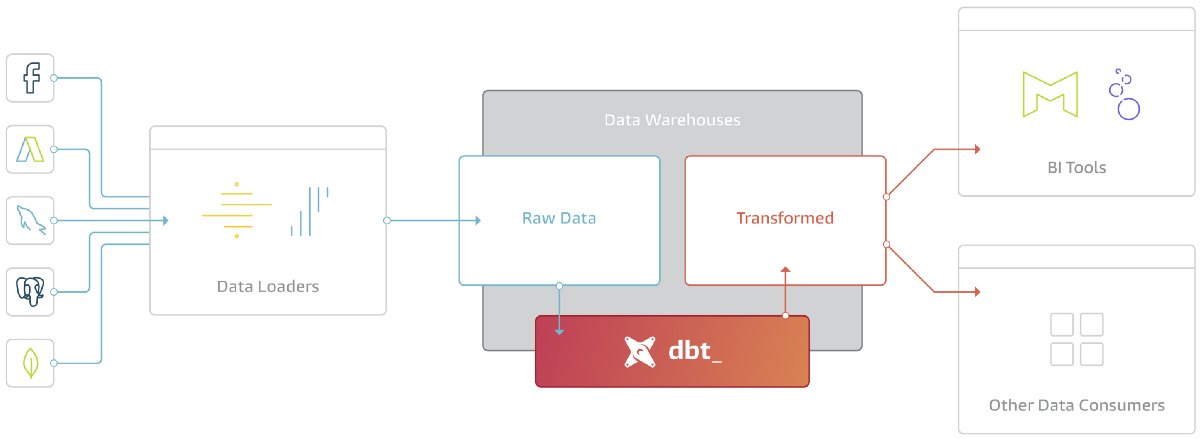
- DBT가 제안하는 Data Platform Stack은 [External Source → Extract & Loader → Warehouse → Consumer] 크게 4개 영역으로 나누고 Warehouse에서 일어나는 모든 Transform을 DBT가 담당하는 것
- DBT는 이러한 데이터 가공 과정을 Modeling이라 표현
- How it works

- SQL, YML로 구성
- SQL 파일에 모델링 작성
- YML 파일에 SQL 파일의 compile에 필요한 설정 값을 작성
- Compiler와 Runner로 구성된 CLI Tool
- Compiler
- SQL, YML 파일을 Compile하여 또 다른 SQL 생성
- Jinja Template Engine 사용
- Runner
- 컴파일된 SQL을 연결된 warehouse에 전달하여 테이블 생성
- 실행 시 의존성을 가지는 모델을 파악해 자동적으로 DAG을 작성, 이에 따라 실행 계획을 만들고 순서대로 실행
- Compiler
- 오픈소스, Pyhton으로 제작, PIP를 통해 설치 가능
- SQL, YML로 구성
- Why & When
- SQL을 코드처럼 작성해야할 때 필요함
- 작성된 SQL의 변경사항을 공유하거나 충돌을 막기 힘듦 → 버전 관리가 필요
- 추출할 지표에 대한 문서화와 공유는 SQL로 이뤄지기 힘듦 → 코드와 연동한 문서화 도구가 필요
- 작성된 SQL을 재활용하기 힘듦 → 부분부분 독립적으로 모듈화하여 재활용
- 작성된 SQL을 테스트하기 힘듦 → SQL에 대한 테스트 도구 필요
- Avaliable Databases
- [BigQuery, Snowflake, Postgres, Redshift, Apache Spark, Databricks, Presto] 연결 지원
기능 및 구성 요소
- Project
- dbt 프로젝트를 의미
- 프로젝트의 설정은 dbt_project.yml에 기록
- 프로젝트의 이름, 데이터세트의 이름 등의 설정
- materialization 설정을 프로젝트/폴더 단위로 설정
- 타겟 설정 (환경 설정의 일종)
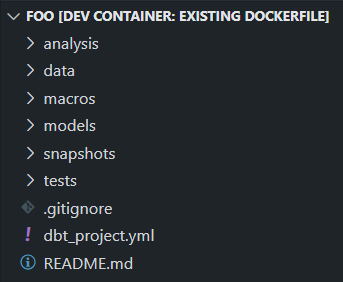
- 프로젝트의 생성은 아래와 같이 실행
1
$ dbt init foo - 실행 결과로 아래와 같은 구조의 폴더/파일이 생성됨
- Model
- select 구문이 포함된 sql 파일
- Jinja Template 사용하여 SQL로 표현이 어려운 코드 작성 가능하다.
- 예시
1 2 3 4 5 6
{{ set columns = ['a', 'b', 'c'] }} select {% for column_name in columns %} {{ column_name }}, {% endfor %} from source_data
- 작성한 모델의 실행은 아래와 같이 입력
1
$ dbt run --models foo
- 최종적으로 생성될 테이블의 이름은 모델의 이름과 동일하게 설정됨
- 작업 환경에서의 폴더 구조와 다르게 데이터세트 하나에 테이블이 저장되므로 모델의 네이밍이 중요.
- 따라서, 모델 상위 디렉터리의 구조를 모델 이름에 중복해 기술해주는 것을 권장
- 예를 들어,
- bad : “foo”
- good : “stg_payments__foo”
- 예를 들어,
- Materialization
- Model을 저장 혹은 유지하는 방법
- 기본적으로 [table, view, incremental, ephemeral] type이 제공됨
- table : 테이블을 신규 생성하거나 기존 테이블이 존재하는 경우 재구축
- view : view table 생성
- incremental : 테이블을 신규 생성하거나 기존 테이블이 존재하는 경우 신규 데이터를 insert하거나 update
- ephemeral : 실제 테이블을 생성하지 않고 다른 모델에서 dependency로 사용할 수 있도록 함
- 예시1. table 생성, date 컬럼에 파티션 추가 설정
1 2 3 4 5 6 7 8 9
{{ config( materialized='table', partition_by={ "field": "date", "data_type": "date" } )}} select * from `project.dataset.table`
- 예시2. incremental 테이블 생성 혹은 업데이트, date 컬럼에 파티션 추가 설정
1 2 3 4 5 6 7 8 9 10 11 12 13 14
{{ config( materialized='incremental', incremental_strategy='insert_overwrite', partition_by={ "field": "date", "data_type": "date" } )}} select * from `project.dataset.table` {% if is_incremental() %} where date >= (select max(date) from {{ this }}) {% endif %}
- incremental model은 이미 생성된 테이블이 존재하는 경우, is_incremental()의 반환값이 true가 되어 하위의 구문이 실행됨. 예시에서는 where 구문에 일자를 조건으로 건 것.
- 최초 실행 시에는 fully refresh, 이후 실행 시에는 조회 범위의 제한을 두어 일부만 가져와 업데이트하는 방식.
- incremental_strategy의 설정에 따라 병합하거나 덮어씌울 수 있음
- 기본적으로 제공되는 네 가지 materialization 외에도 custom materialization을 작성할 수 있음
- Creating new materializations에서 상세한 내용 참조
- Test
- Model이 의도에 맞게 작성되었는지 테스트하기 위한 도구
- 아래와 같이 실행
1
$ dbt test
- 크게 두가지 테스트 방법이 존재 - [Schema, Data]
- Schema Test
- unique, not_null, accepted_values, relationships 둥 지정한 컬럼의 값이 조건을 만족하는지 확인
- Model이 소속되어 있는 폴더 내의 schema.yml에 설정
- 기본적으로 제공되는 macro외에도 custom macro를 직접 만들어 테스트 가능
- 예시
1 2 3 4 5 6 7 8 9
version: 2 models: - name: orders columns: - name: order_id tests: - unique - not_null
- Data Test
- tests directory의 sql을 실행 후 실행 결과의 row 유무에 따라 테스트 실패를 판단
- 예시
1 2 3 4 5 6
select order_id, sum(amount) as total_amount from {{ ref('stg_payments') }} group by 1 having not(total_amount >= 0)
- Schema Test
- Documentation
- 제작한 모델에 대한 문서를 생성한다.
- 생성된 문서는 웹 페이지 형태로 제공됨
- 아래 명령을 실행해 문서를 생성함
1
$ dbt docs - 생성된 문서의 예시
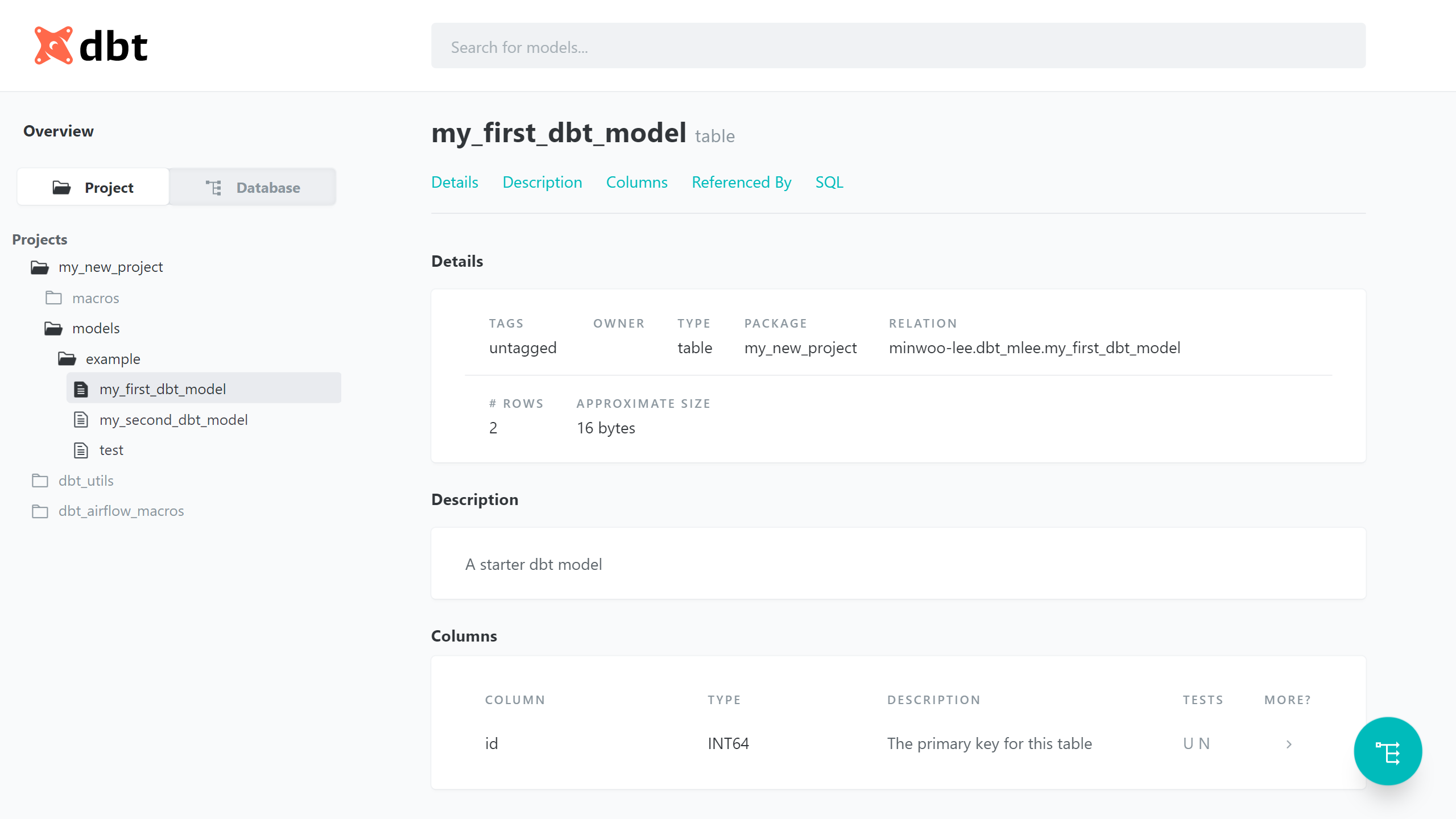 생성한 모델에 대한 설명, 컬럼 안내, SQL을 조회할 수 있다.
생성한 모델에 대한 설명, 컬럼 안내, SQL을 조회할 수 있다.
 생성한 모델의 의존성을 파악할 수 있도록 시각화하여 제공한다.
생성한 모델의 의존성을 파악할 수 있도록 시각화하여 제공한다.
- Macro
- 다수 Model에서 재사용할 수 있도록 작성된 Jinja 코드, 함수의 일종
- 예시
- cents_to_dollars.sql
1 2 3
{% macro cents_to_dollars(column_name, precision=2) %} ({{ column_name }} / 100)::numeric(16, {{ precision }}) {% endmacro %}
- macro의 구현 또한 sql 파일로 작성한다.
- my_model.sql
1 2 3 4
select id as payment_id, {{ cents_to_dollars('amount') }} as amount_usd from app_data.payments
- 작성해둔 cents_to_dollars macro를 모델에서 사용하기 위해서는 jinja template으로 감싸 사용한다.
- 위 모델을 컴파일하면 아래와 같은 결과
1 2 3 4
select id as payment_id, (amount / 100)::numeric(16, 2) as amount_usd from app_data.payments
- cents_to_dollars.sql
- Macro를 위한 Package Manager가 제공됨
실행
- 모델을 테이블로 만드는 모든 과정은
Run을 통해서 진행 - Arguments
- profile : 연결할 profile의 설정, dbt_project.yml의 값을 overriding
- vars : macro 등에서 사용될 변수를 전달
- models
- 특정 모델을 선택하여 실행한다.
+기호를 사용하여 지정한 모델의 전/후 DAG을 일괄 실행하도록 설정할 수 있다.- 예시1.
my_first_dbt_modelmodel 실행1
$ dbt run --models my_first_dbt_model
- 결과로 my_first_dbt_model 테이블이 생성된다.
- 예시2.
my_first_dbt_modelmodel과my_first_dbt_model에 의존성을 가지는 모든 모델 실행1
$ dbt run --models my_first_dbt_model+
- 결과로 my_first_dbt_model, my_second_dbt_model 모델이 생성된다.
- 예시3.
my_second_dbt_modelmodel과my_second_dbt_model이 의존성을 가지는 모든 모델 실행1
$ dbt run --models +my_second_dbt_model
- 결과로 my_first_dbt_model, my_second_dbt_model 모델이 생성된다.
- full-refresh
- incremental model인 경우 drop 후 rebuild 하도록 설정한다.
- Scheduling
- dbt 자체적으로 Scheduling Run하는 방법이 없으므로 Airflow 등의 외부의 도구가 필요
- dbt의 제작자인 dbt labs가 운영하는 dbt cloud는 이러한 scheduling tool을 제공
모델 구성
-
dbt의 모델링 과정에서 느슨하게 약속된 몇 가지 개념/용어들이 존재 (강제 사항이 아님)
- Model / Modeling
- Transform이 완료된 데이터 / Transform 과정을 의미함
- Source Model
- Raw Data를 의미함
- Staging Model
- Source와 1:1 대응하는 모델을 의미
- 데이터를 깔끔하게 정리하거나 표준화하는 등의 단순한 작업을 거친 모델
- Intermediate Model
- Staging Model에서 Reporting 등의 Consumer가 직접 사용하는 최종 Model 사이의 모델을 의미
- 이 부분부터 정의가 애매한 편 혹은 자유도가 높음. 프로젝트 혹은 용도에 따라 맞춰 사용
- Fact Model
- 지표 저장을 위한 모델
- Dimension Model
- Dimension 저장을 위한 모델
- Source / Staging / Fact / Dimension 으로 구성된 모델 흐름의 예시
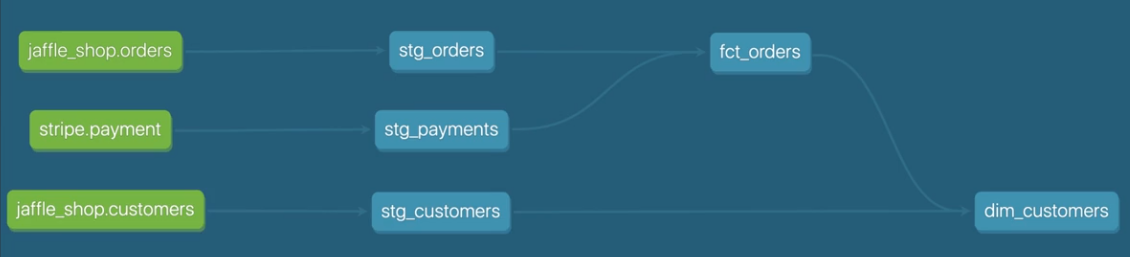
- 예시와 같이 모델들을 구성하는 과정은 자유로운 편, 위와 같은 구성이 강제적이지 않다.
- 공식 문서의 FAQs → Example Project를 확인해보면 Source, Staging Model 까지는 공통, 이후부터의 구현은 프로젝트에 따라 다름
dbt Cloud
- Managed dbt service
- 1인 사용 시 무료, 팀 협업 시 유료
- 장점 : 간편하게 설정하고 실행할 수 있는 custom running environment, job scheduling, logging, documentation deploy
-
단점 : 일반적인 IDE에 비해 떨어지는 편집기, 가끔 보이는 버그 / 불안정한 동작, 아쉬운 UI/UX, 터미널을 통한 환경 접근 불가능 → custom macro 작성시 상당히 불편함
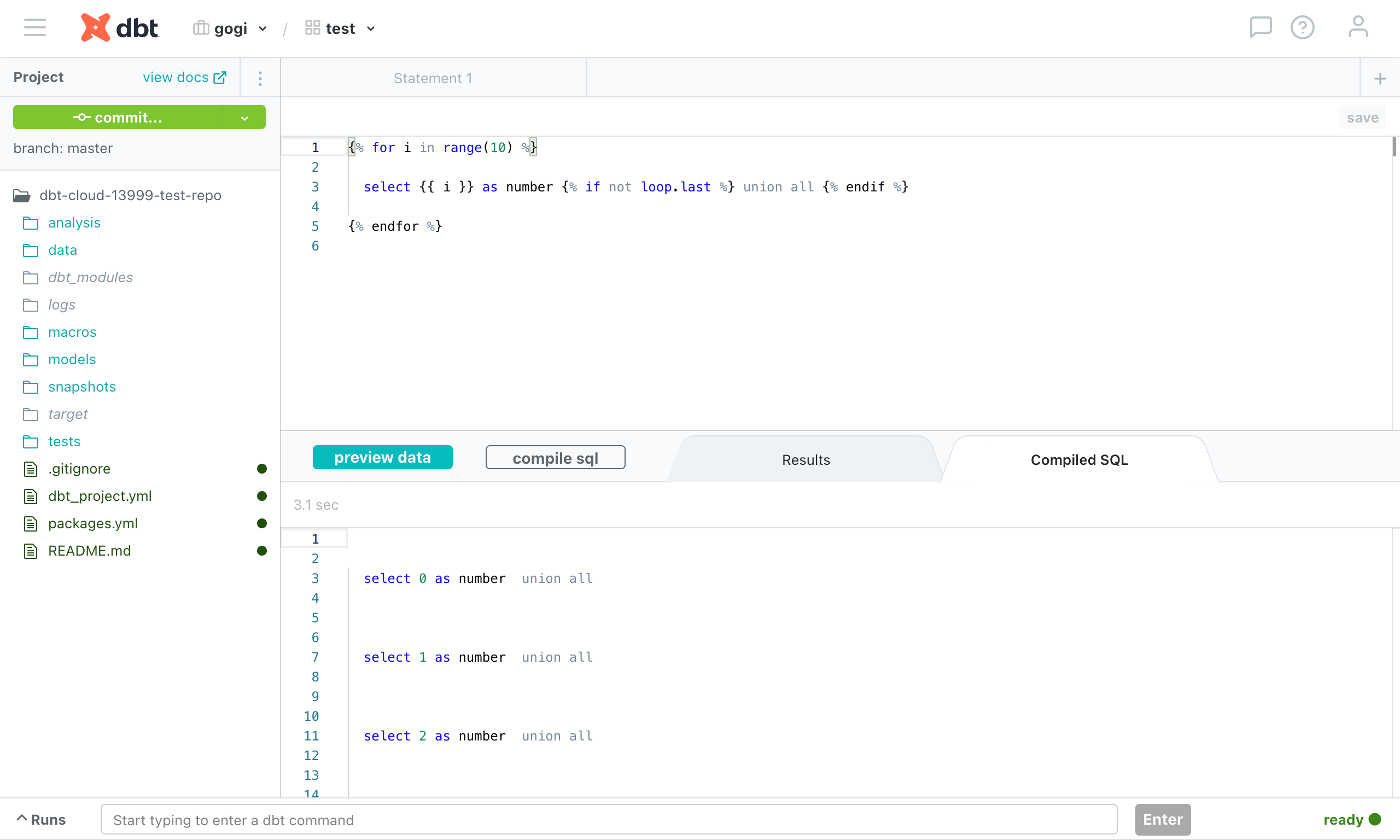 편집기
편집기
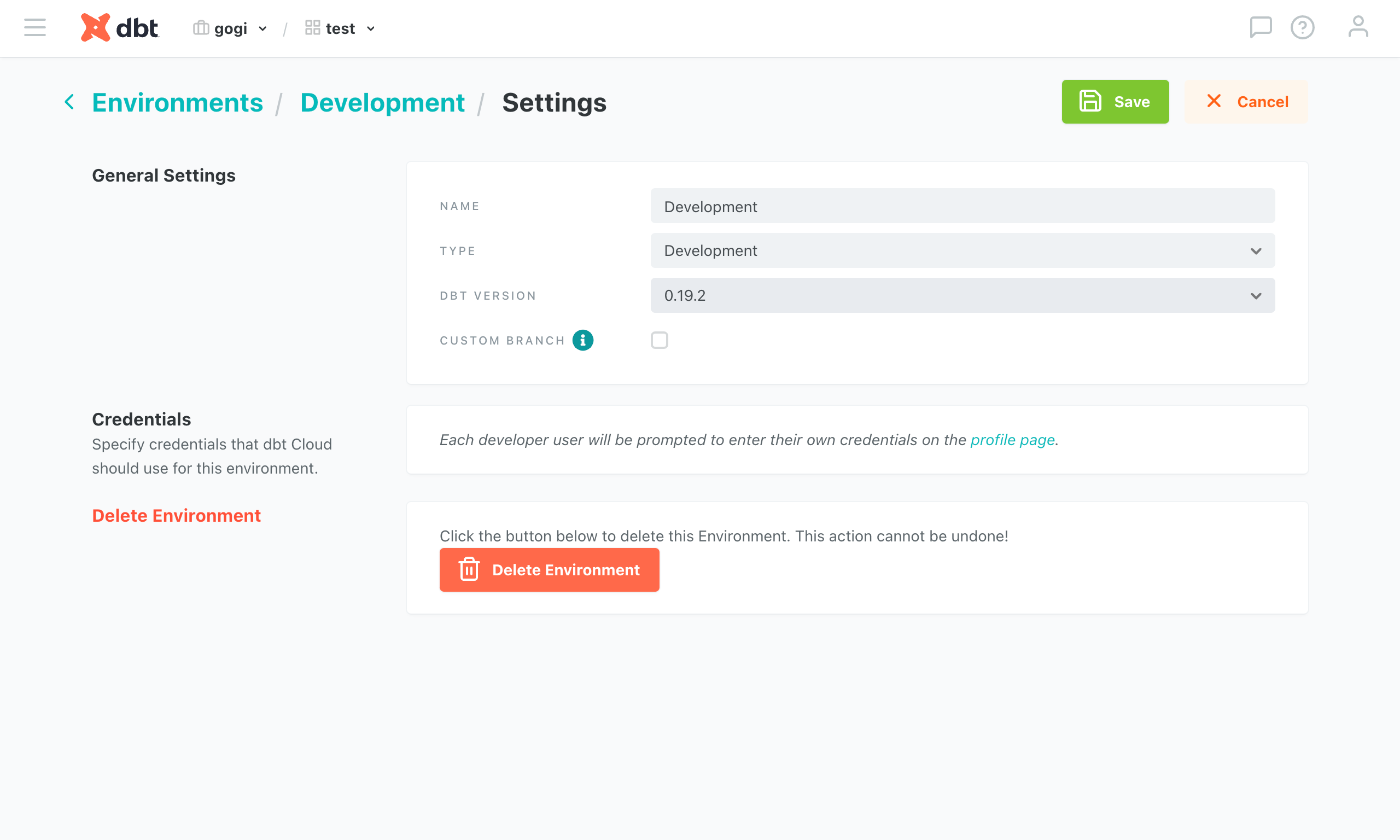 dbt가 실행될 환경에 대한 설정
dbt가 실행될 환경에 대한 설정
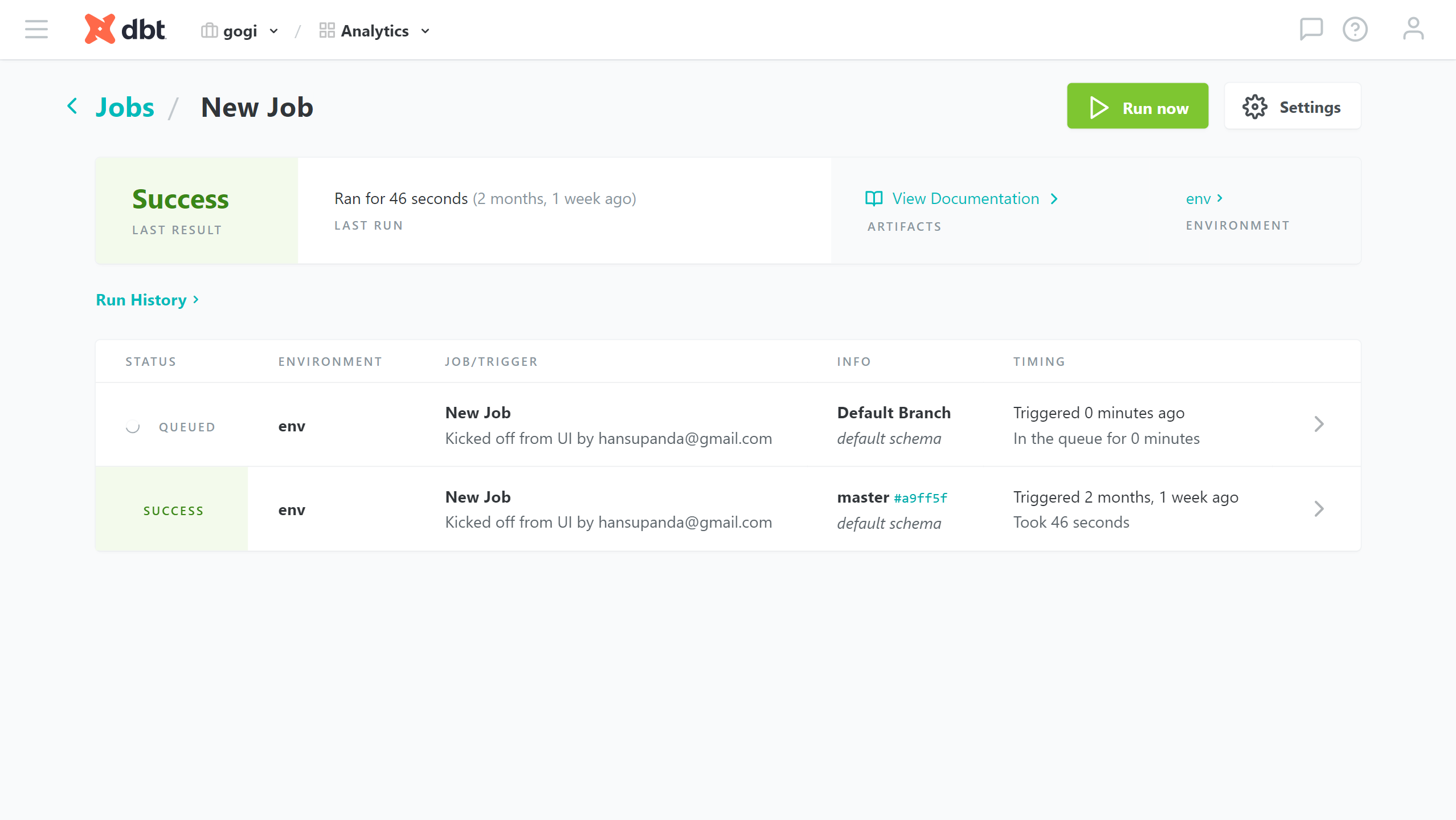 실행된 job들의 목록
실행된 job들의 목록
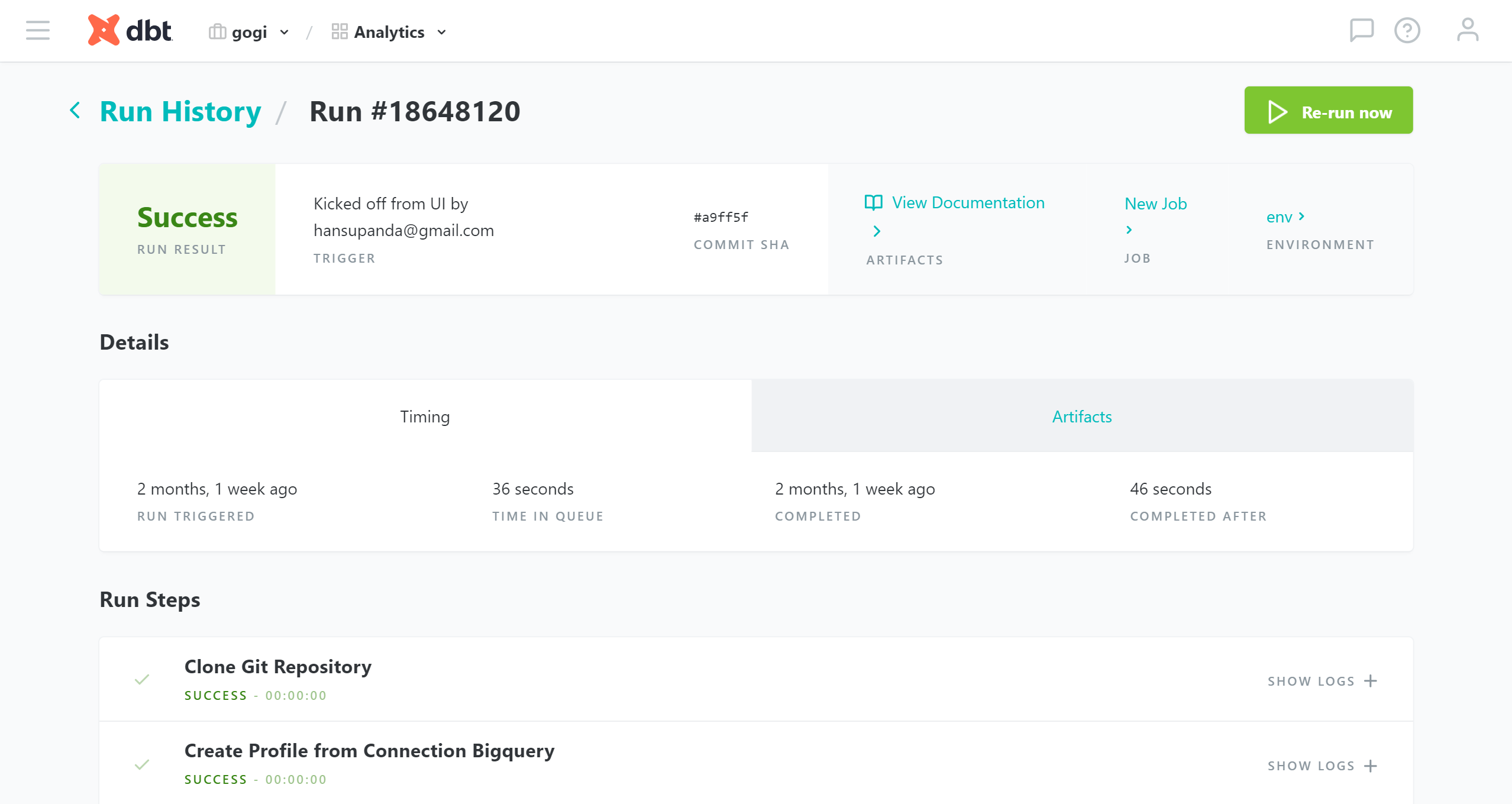 실행된 job의 상세 정보
실행된 job의 상세 정보
 설정, 프로젝트나 팀메이트 초대 등이 가능
설정, 프로젝트나 팀메이트 초대 등이 가능
사용 후 의견
- 비용과 성능 걱정이 적다.
- BigQuery, Snowflake, Redshift에서라면 비용/성능 고민없이 다수의 transform을 만들 수 있게 될 것
- 단순히 컴파일/명령을 전달하는 도구이므로 dbt 동작이 위해 큰 퍼포먼스를 요구하지 않는다. → 큐잉, 밸런싱 등의 엔지니어링 부담 없이 운영 가능하다.
- 데이터 조직의 기능을 개선할 도구
- 모델링 작업을 통해 데이터를 개선한다.
- 데이터 조직 내에서도 쿼리를 작성하고 공유하거나 유지보수하는 것이 상당히 원시적인 경우가 많다.
- dbt는 버전 관리, 모듈화, 모델링의 레이어 구분 등. 운영에 필수적인 요소를 갖추고 있다. 일반적인 데이터 조직에서 이러한 필수적인 요소를 잘 갖추지 못한 경우가.. 적지 않을 것이다.
- 테스트를 통해 신뢰를 구축한다.
- 데이터 조직 내에서도 작성한 쿼리의 결과를 믿지 못하는 경우가 많다.
- 잘못된 데이터의 유입이나 잘못된 쿼리 등등, 스스로를 믿는 좋은 방법이 될 것이다..
- 문서화를 통해 공유를 용이하게 한다.
- 작성한 마트로의 물리적인 접근은 쉽다해도 마트에 대한 안내 없이는 외부 조직에서 쉽게 사용할 수 없다.
- 데이터 리니지, 테이블이나 컬럼 등에 대한 안내가 외부 조직의 접근성을 높이는데 도움이 될 것이다.
- 모델링 작업을 통해 데이터를 개선한다.
- Transform에 진심인 편..
- 기존 ETL, ELT 작업을 관리하던 Job이 있다 해도, 완전히 독립적인 T만을 지향한다.
- 기존 데이터세트에 덮어씌우는 대신 dbt 전용의 데이터세트를 구성한 뒤, merge하는 방식을 권장 / merge는 dbt가 아닌 다른 도구로..
- Transform 과정에서 stateless를 극단적으로 유지하는 것을 권장
- 원론적으로는 동의하고 맞는 말이지만, 레거시와 병합하는 과정에서는 괴로울 것..
- 다소 불편한 UX
- SQL 작성 시 문법 오류 확인이 어렵다.
- 컴파일 결과를 dry run하기 전까지는 작성한 쿼리의 오류 여부를 확인할 수 없다. 따라서 작성→컴파일→수정→컴파일 과정을 불필요하게 반복하게 된다.
- materialization의 구현을 직접 확인하기 전까지는 실제 컴파일 결과를 예상하기 어렵다. 사용자는 select statement만 작성하지만 실제 컴파일 결과에는 drop / create 등의 구문이 추가된다.
- 컴파일 결과를 볼 때 불편하다.
- models 폴더에 작업하고 동일한 이름의 파일로 target 폴더에 결과가 저장된다. 오류를 수정하고 컴파일 결과 파일을 수정하는 경우가 허다하다.
- 매크로 작업이 다소 불편하다.
- 기존 사용 가능한 매크로에 대한 안내가 부족해 일일히 코드 저장소를 찾아봐야 한다.
- Python으로 작성된 adapter 기능의 안내 또한 매우 부족하며, custom으로 만들기 어렵다. 따라서 다소 복잡한 요구사항의 macro를 구현하는데에 제한이 크다.
- 매크로 작성 시의 오류를 디버깅하는 것이 어렵다.
- Package Manager가 제공되나.. npm pip 등과 비교해 사용 방법이 난해한 편
- SQL 작성 시 문법 오류 확인이 어렵다.
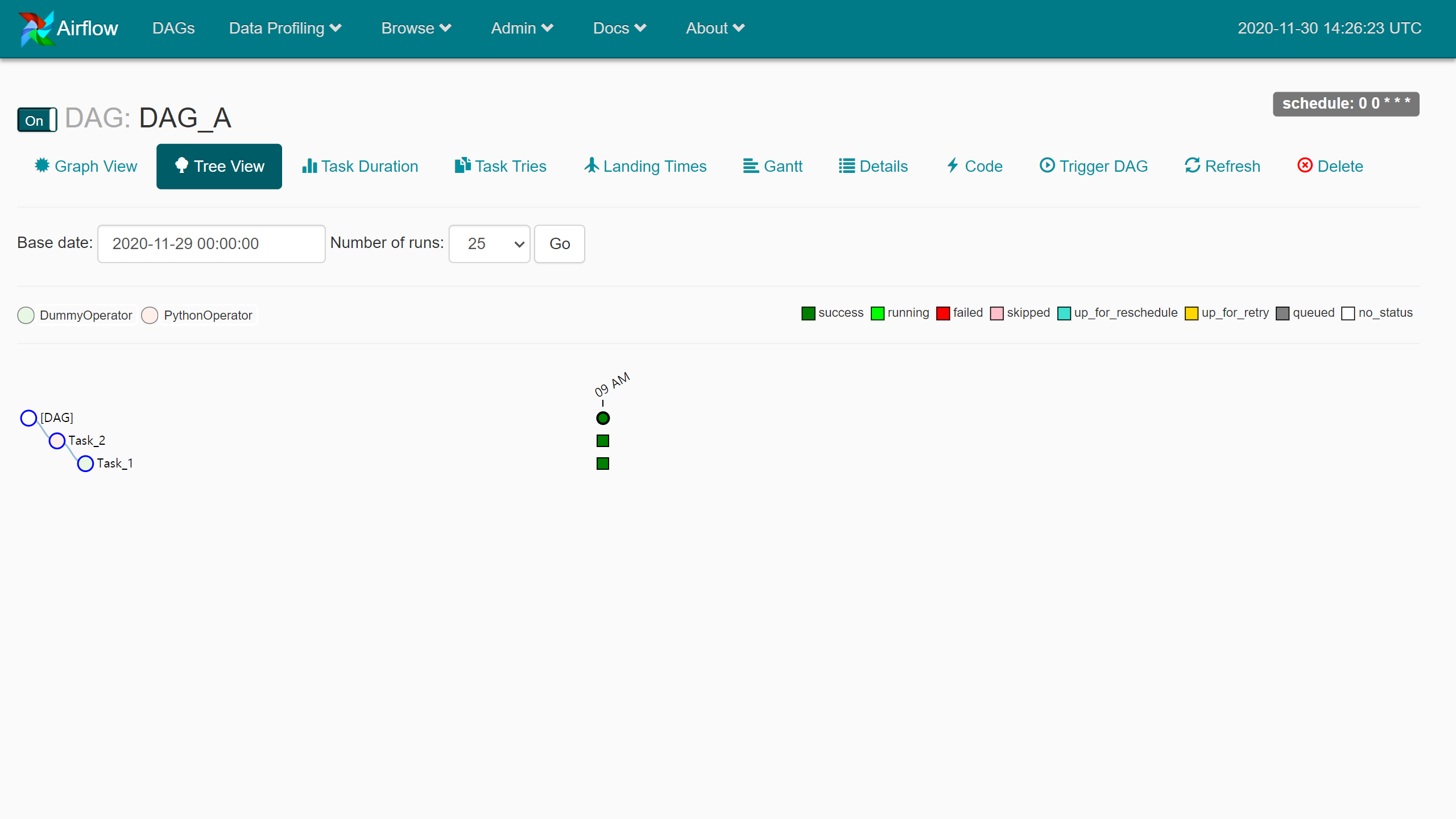
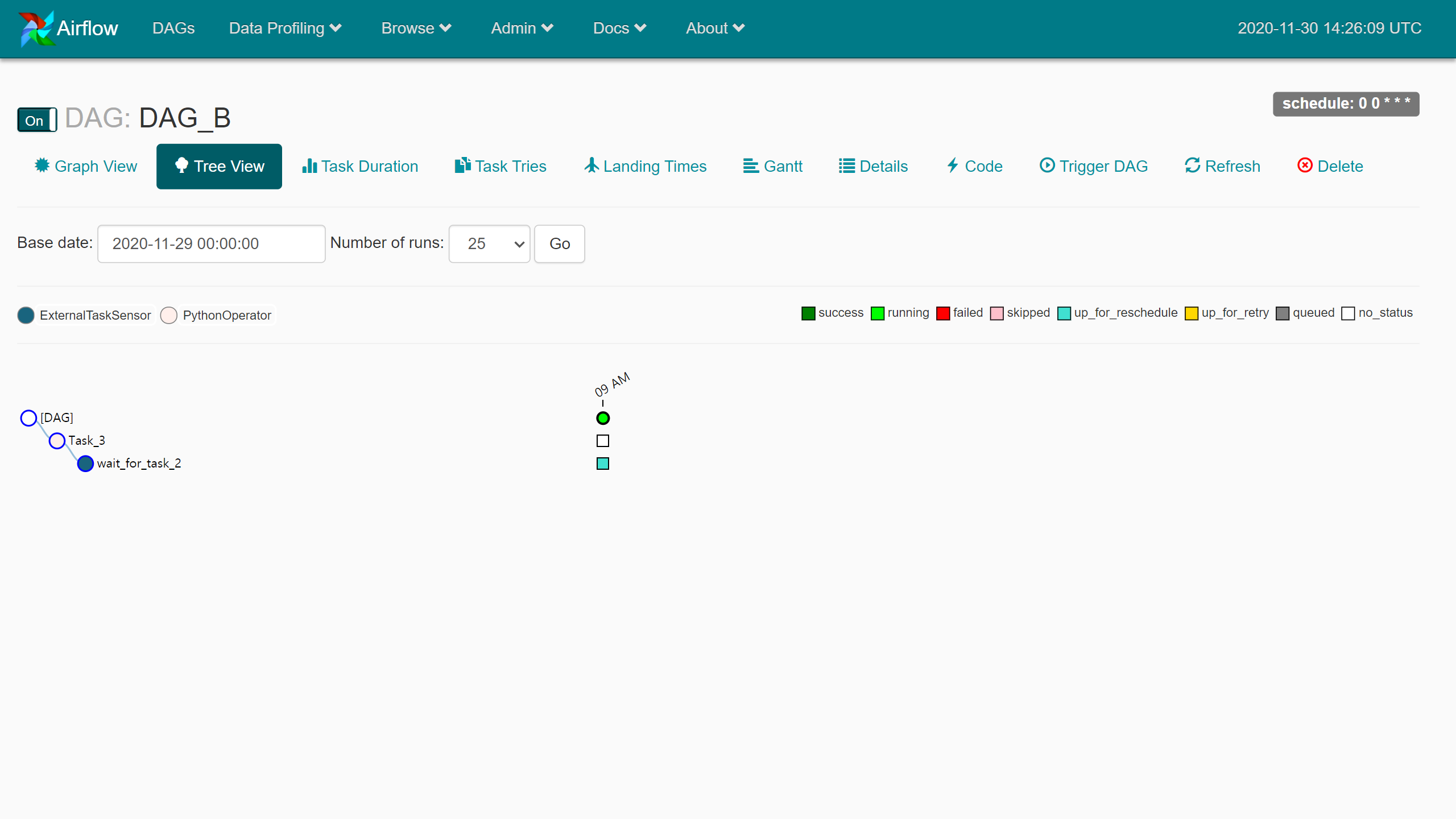 이 상태에서 일정 시간마다 DAG_A 모니터링을 시작한다.
이 상태에서 일정 시간마다 DAG_A 모니터링을 시작한다.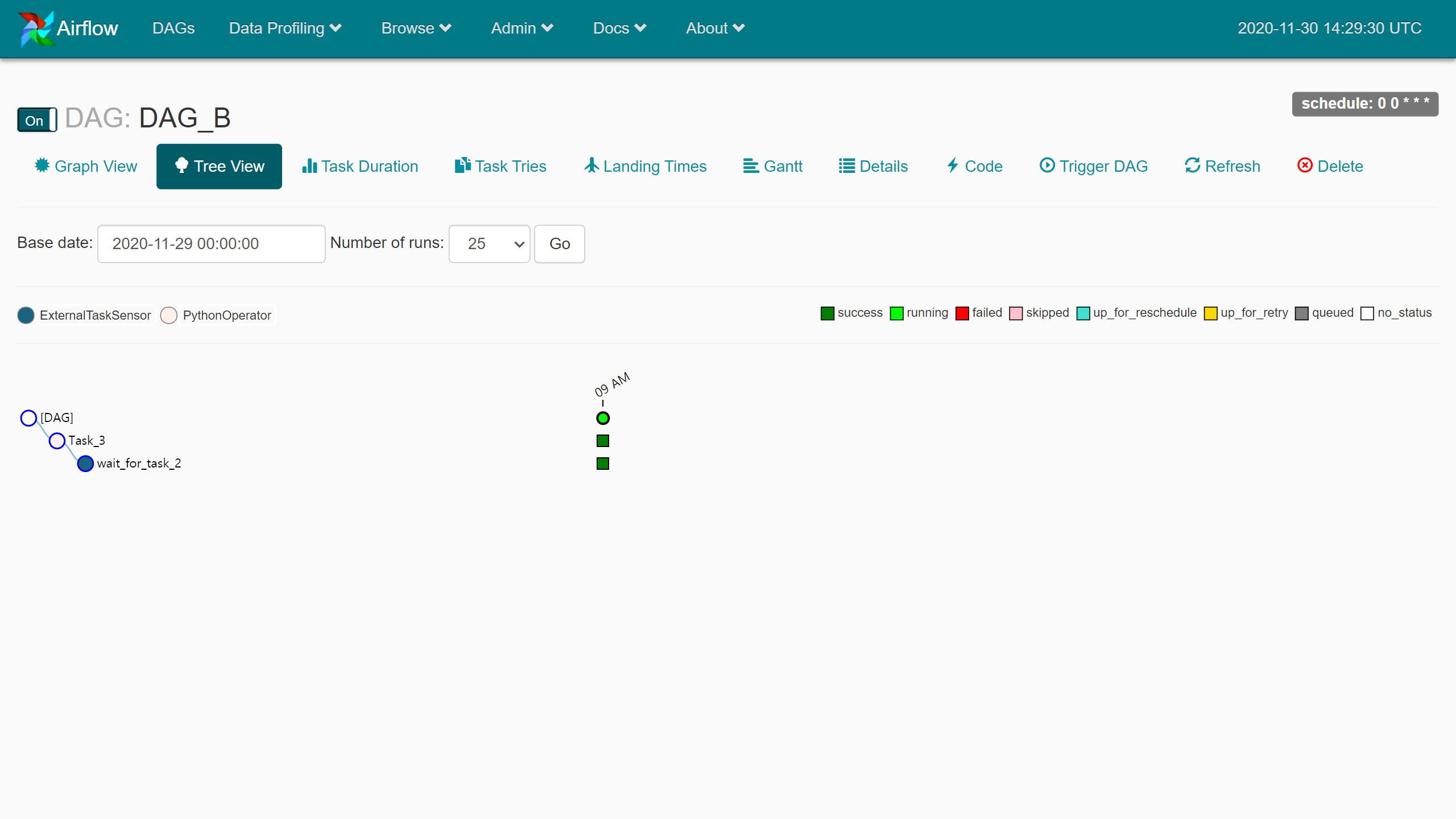 모두 성공한 상태가 되었다.
모두 성공한 상태가 되었다.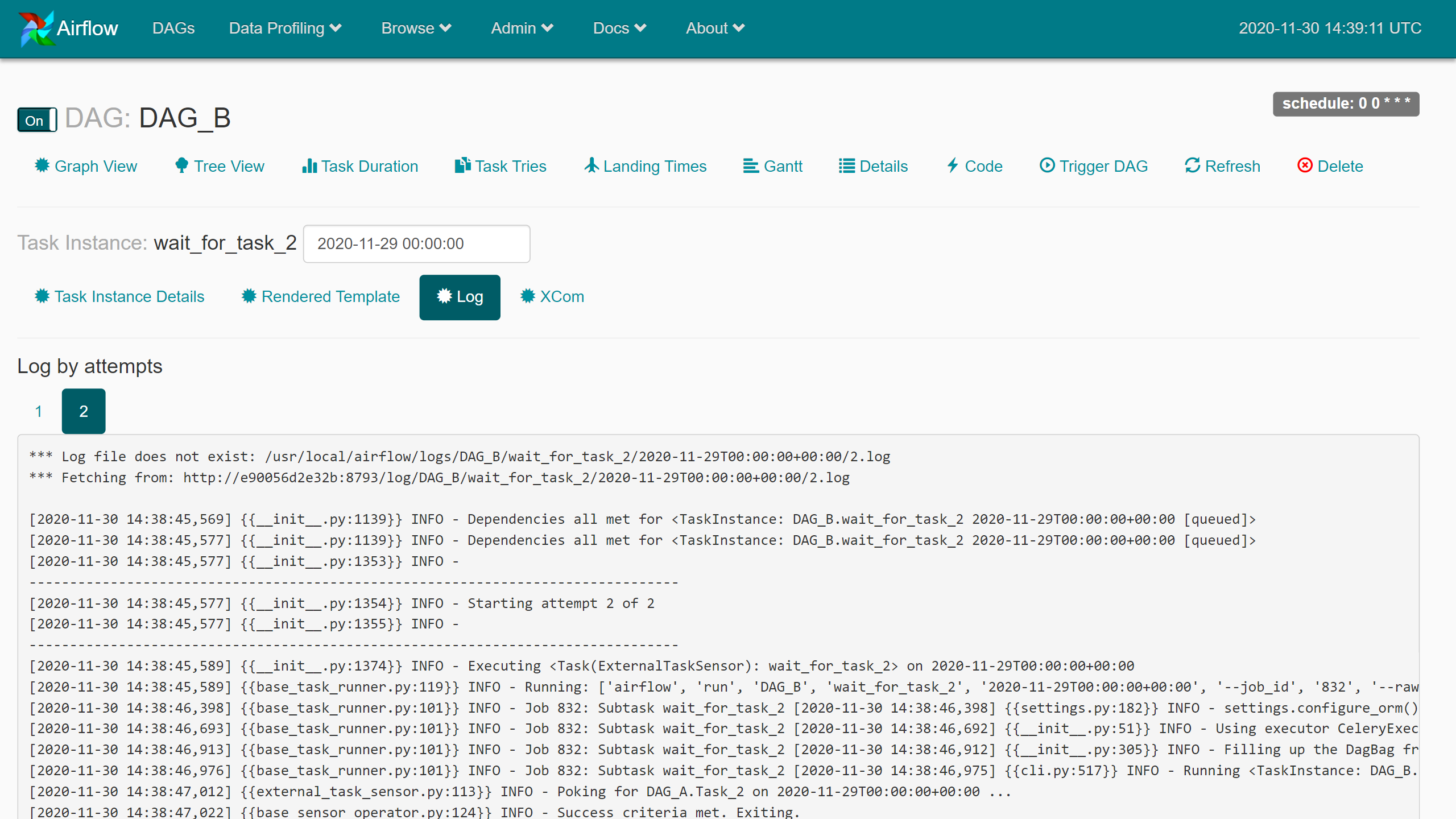 …Poking for DAG_A.Task_2.. 설정한 id들이 적절했는지 여기서 확인한다.
…Poking for DAG_A.Task_2.. 설정한 id들이 적절했는지 여기서 확인한다. 계정이 없는 경우 첫 페이지
계정이 없는 경우 첫 페이지
 계정 이름 설정
계정 이름 설정
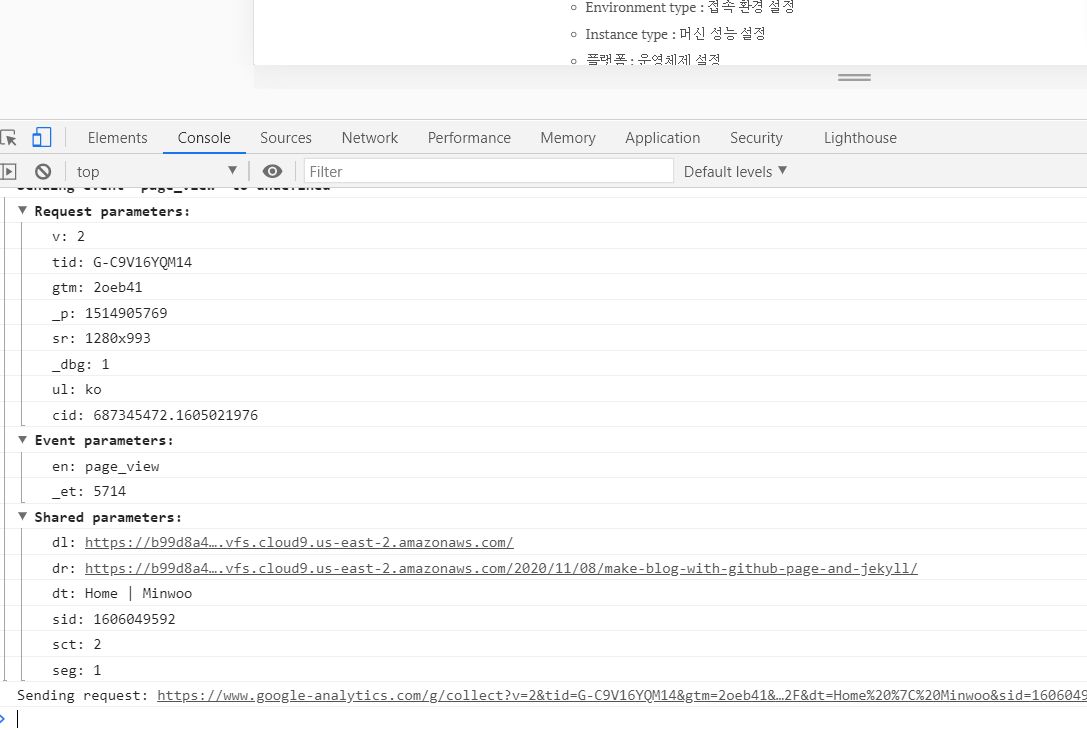
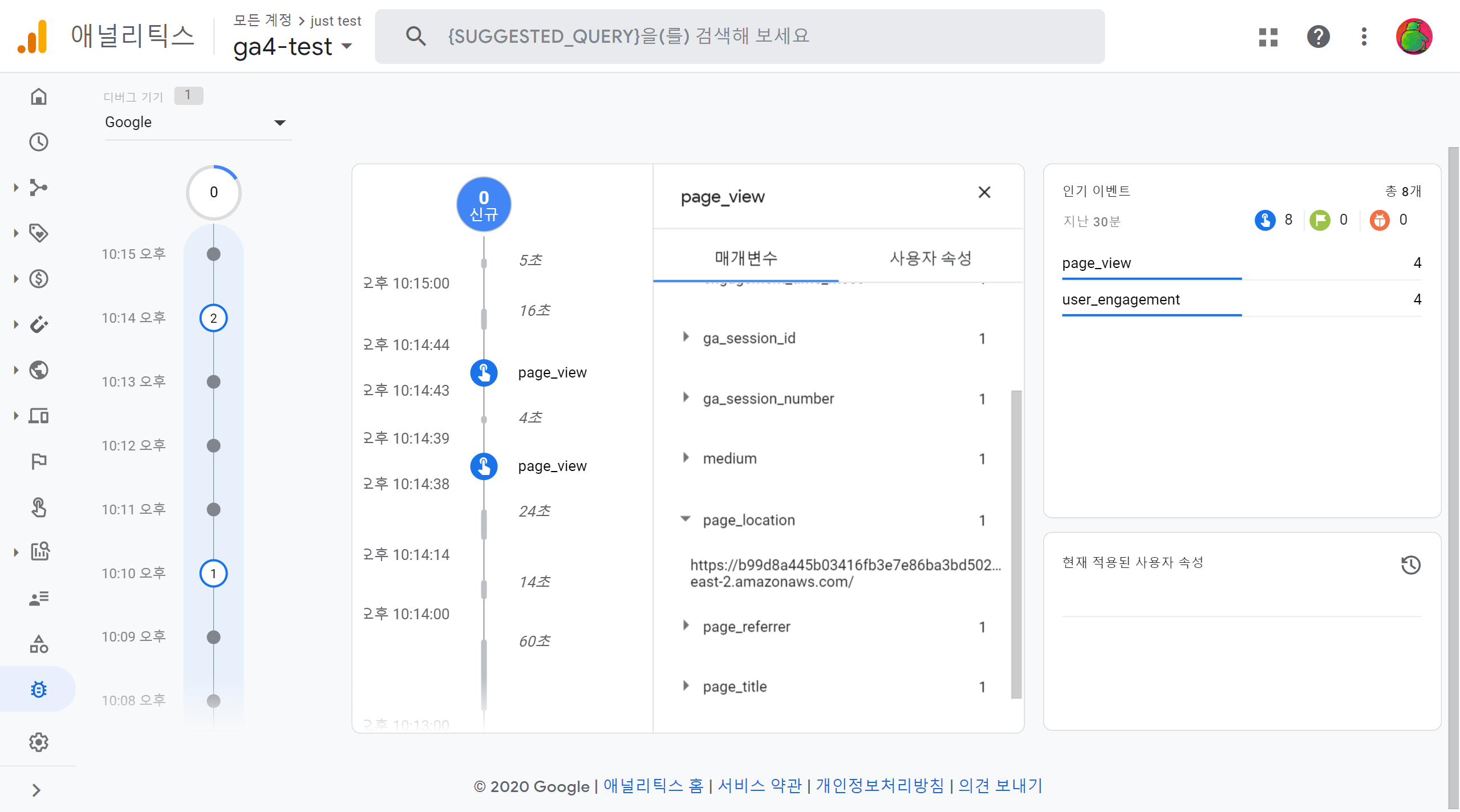
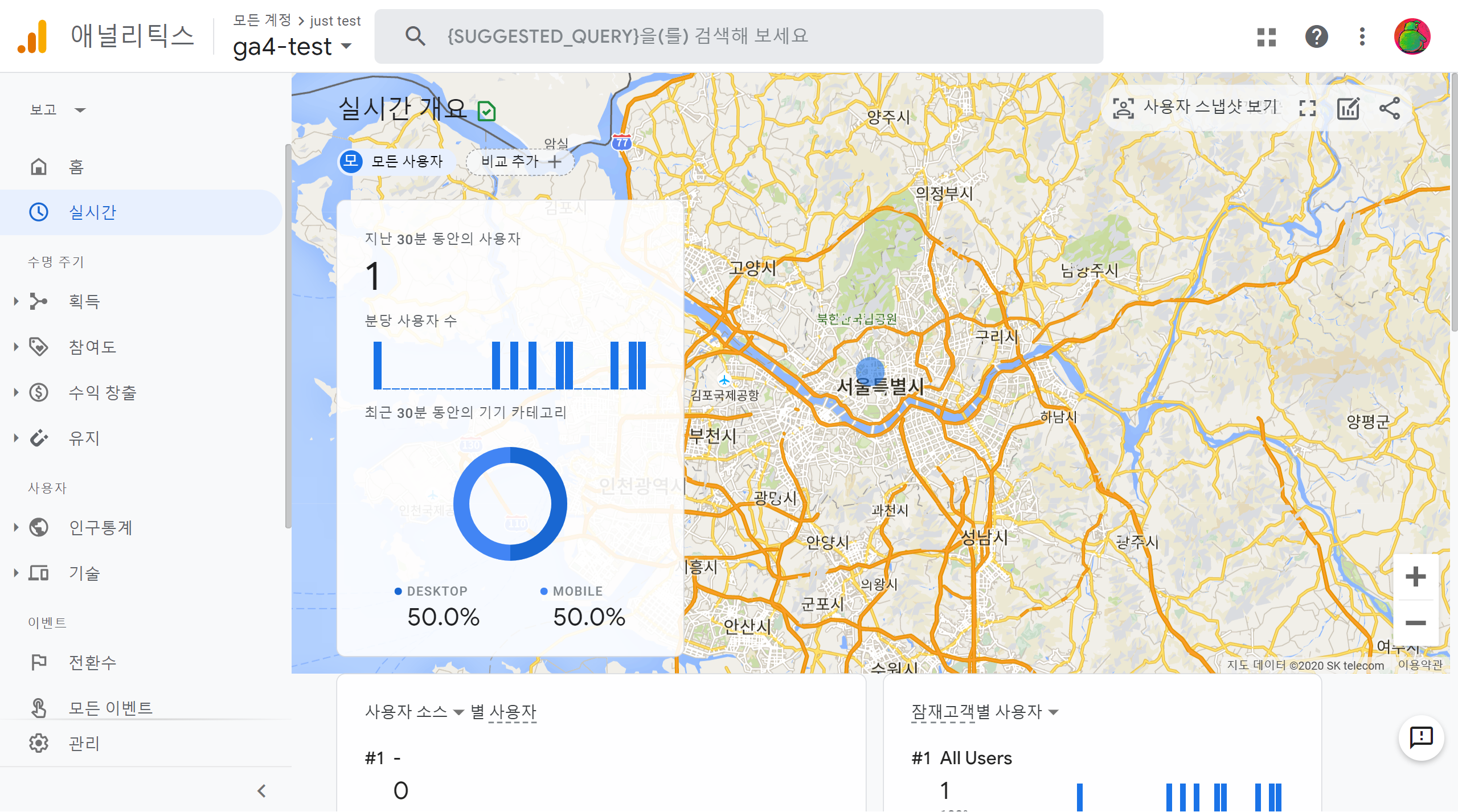
 Cloud9 첫 화면
Cloud9 첫 화면 Cloud9 생성 시 설정들
Cloud9 생성 시 설정들 생성 완료된 IDE
생성 완료된 IDE cloud9 접속 중인 화면
cloud9 접속 중인 화면 cloud9 첫 화면
cloud9 첫 화면